—多线程—
在Linux下线程是最小的执行单位,调度的基本单位。
相关基础内容转到linux多线程专题查看。
起源是我背八股文的时候背这个问题:
线程的共享资源和私有资源有哪些?
给出的答案:线程共享资源:进程代码段、进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)、进程打开的文件描述符、信号的处理器、进程的当前目录和进程用户ID与进程组ID。
线程私有资源:线程ID、寄存器组的值、线程的堆栈、错误返回码、线程的信号屏蔽码、线程的优先级
其它我能理解,但是私有资源中的线程堆栈的堆为何是私有资源,我始终想不明白,于是为了解决这个问题,我打算从 创建线程的底层原理入手。
在linux中创建线程通常用 pthread_create()接口, 它其实是一个库函数,可传入四个参数,分别代表的是 线程id指向的内存空间、线程属性、子线程函数入口、子线程函数传入的参数。在调用 pthread_create()函数的时,会先在用户态为其创建自己的栈,用宏定义ALLAOCTE_STACK表示,用户态的相关信息用pthread结构体表示。随后调用clone()系统调用陷入内核态,接着进入create_thread()真正创建线程,随后调用_do_work() –> copy_process()函数用来对 task_struct 这个结构体填充相关信息,因为是线程创建,copy_process()仅仅是使各个结构体引用计数+1,随后返回用户态。
可以看到线程创建过程中没有提到堆的创建,而是只有各自的栈,
于是我认为 linux 中一个进程中的所有线程共享该进程的堆区,而线程各自的堆说的是一些线程感知的分配器将对堆进行分区,以便每个线程都有自己的区域可供分配。
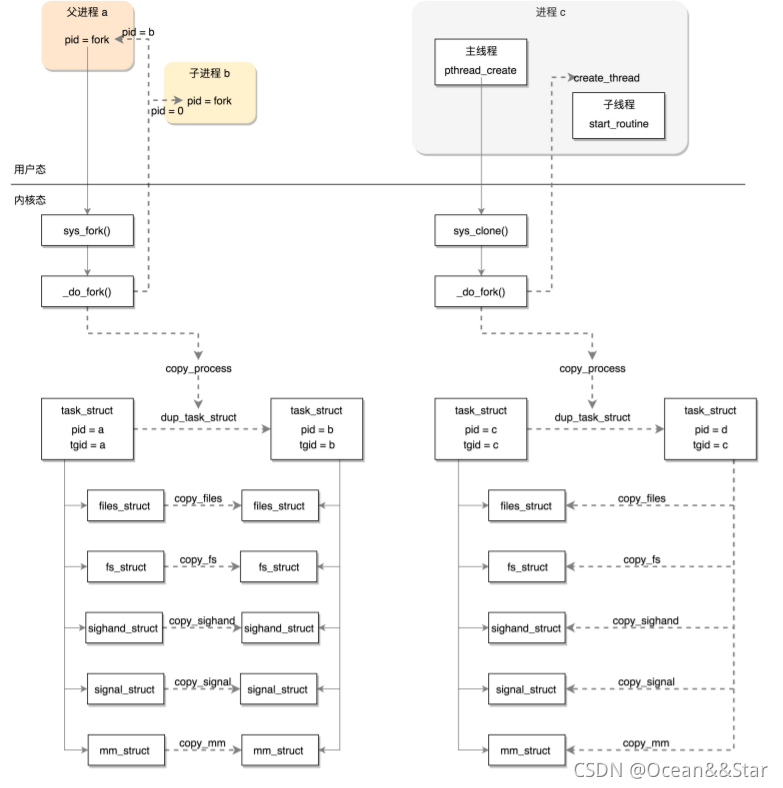
这个是 linux下 fork()创建进程, pthread_create()创建线程的用户态与内核态流程图的不同:
- 创建进程的话,调用的系统调用是fork,在copy_process函数里面,会将五大结构files_struct、fs_struct、sighand_struct、signal_struct、mm_struct 都复制一遍,从此父进程和子进程各用个的数据结构。
- 创建线程的话,调用的是系统调用clone,在copy_process函数里面,五大结构仅仅是引用计数加一,也就是线程共享进程的数据结构
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 351134995@qq.com

